Вас обмануть проще, чем кажется. Наука назвала главный триггер наших иррациональных решений
Каждый день мы принимаем десятки, если не сотни, решений. Что съесть на завтрак? Какой дорогой поехать на работу? Стоит ли соглашаться на новый проект? Большинство из них мы совершаем на автопилоте. Но когда ставки растут, а правила игры усложняются, что-то меняется. Мы начинаем сомневаться, просчитывать ходы, и… нередко ошибаемся. Почему так происходит? Почему наша блестящая логика порой даёт сбой именно тогда, когда она нужнее всего?
Долгое время экономика и социальные науки опирались на образ «человека рационального» (Homo economicus) — идеализированного существа, которое всегда действует с холодной расчётливостью и выбирает единственно верный путь к максимальной выгоде. Но, как мы все знаем по собственному опыту, реальность далека от этой модели. Новое исследование, проведённое учёными из Принстона и Бостона, не просто подтверждает этот факт, а делает нечто большее: оно показывает, что наша рациональность — это не константа, а переменная величина, напрямую зависящая от сложности задачи.

Прощай, равновесие Нэша?
Чтобы понять всю прелесть нового открытия, нужно сделать небольшой шаг назад. В теории игр десятилетиями царила концепция «равновесия Нэша». Если говорить просто, это такая ситуация в игре, когда ни один из участников не может улучшить своё положение, изменив свою стратегию в одностороннем порядке. Предполагается, что все игроки — гениальные аналитики, способные мгновенно просчитать все варианты и прийти к этому самому равновесию.
Проблема в том, что в реальных экспериментах люди ведут себя иначе. Они отклоняются от «идеального» курса, совершают нелогичные, на первый взгляд, поступки. Поведенческая теория игр пыталась объяснить эти «аномалии», создавая десятки моделей, которые учитывали бы психологию, эмоции и когнитивные искажения. Но ни одна из них не давала универсального ответа. До сих пор не было ясно, какая модель лучше и, главное, почему в одних ситуациях мы почти идеальные стратеги, а в других — действуем непредсказуемо.
Нейросеть-психолог: новый взгляд на старую проблему
И вот здесь на сцену выходит искусственный интеллект. Исследователи поставили перед собой амбициозную задачу: не просто найти ещё одну модель, а провести своего рода «очную ставку» между всеми существующими теориями. Для этого они использовали глубокие нейронные сети — мощный инструмент, способный находить скрытые закономерности в огромных массивах данных.

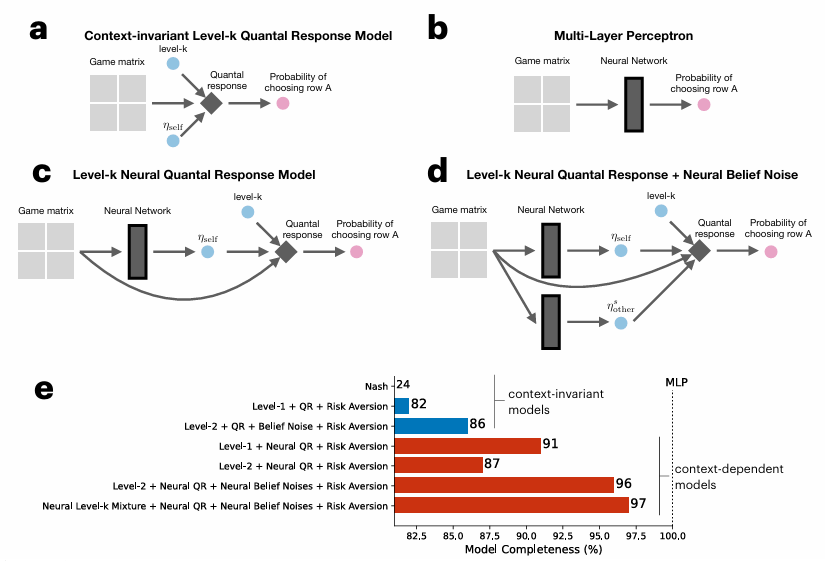
Но они пошли хитрым путём. Вместо того чтобы просто «скормить» нейросети данные и получить «чёрный ящик», который предсказывает поведение, но не объясняет его, они создали гибридную модель. Представьте себе аудиомикшер. В его основе лежит классическая поведенческая модель (модель квантильного отклика), которая уже допускает, что в наши решения вкрадывается некий «шум» или случайность. А роль звукорежиссёра, который крутит ручку этого «шума», выполняет нейросеть.
Именно нейросеть анализирует условия игры — её правила, возможные выигрыши и проигрыши — и предсказывает, насколько «шумным», то есть иррациональным, будет поведение человека в данном конкретном контексте. Это и стало прорывом.
Главный вывод: чем сложнее игра, тем громче «шум»
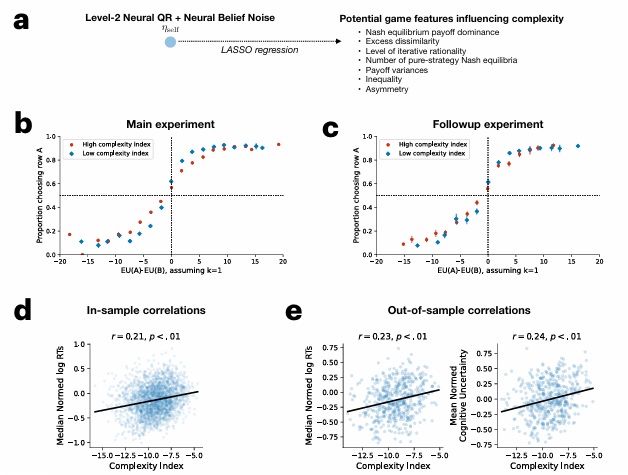
Результаты оказались поразительно изящными. Гибридная модель показала, что уровень «поведенческого шума» напрямую связан со сложностью игры, как её воспринимает человек.
- В простых играх, где правила ясны, а выгоду легко просчитать, люди ведут себя очень близко к рациональному идеалу. «Шум» минимален, а их действия предсказуемы.
- В сложных играх, требующих глубоких многоходовых рассуждений или сложных арифметических подсчётов, наша когнитивная система, кажется, перегружается. Рациональное ядро поведения никуда не девается, но его заглушает тот самый «шум». Мы начинаем полагаться на интуицию, эмоции, упрощённые эвристики, и наши решения становятся менее предсказуемыми и оптимальными.
Исследователи даже выделили факторы, делающие игру «сложной» для нашего мозга: необходимость анализировать эффективность ходов, трудность математических расчётов и глубина логической цепочки, которую нужно выстроить для победы. Проще говоря, чем больше нужно думать, тем выше вероятность, что мы ошибёмся или пойдём более простым, но неверным путём.
За стенами лаборатории: почему это важно для каждого из нас?
Это исследование — не просто очередное упражнение для учёных. Оно проливает свет на то, почему мы так уязвимы в современном мире. Сложные финансовые продукты, запутанные условия договоров, многоуровневая политическая пропаганда — всё это примеры «сложных игр», в которые нас вовлекают. Создатели таких систем, сознательно или нет, эксплуатируют эту особенность нашего мышления. Повышая сложность, они увеличивают наш «поведенческий шум», делая нас более сговорчивыми и склонными к невыгодным для себя решениям.
Понимание этого механизма открывает дорогу к созданию защиты. Если мы знаем, что сложность перегружает нашу рациональность, мы можем научиться распознавать такие ситуации и требовать упрощения информации. Компании могут создавать более понятные интерфейсы, а государства — более прозрачные законы.
В конечном счёте, эта работа показывает, что нет никакого «человека рационального» и «человека иррационального». Есть просто человек реальный, чья способность к логическому анализу — это мощный, но ограниченный ресурс. И чем лучше мы поймём пределы этого ресурса, тем более осмысленные и безопасные решения сможем принимать как для себя, так и для всего общества.